相关概念视频
 01:19
01:19Role of Shaping in Operant Conditioning
322
Shaping is a technique used in operant conditioning to train complex behaviors by rewarding successive approximations toward the target behavior. This method is necessary because organisms are unlikely to perform complex behaviors spontaneously. Instead, shaping breaks down the desired behavior into small, manageable steps.
The steps involved in shaping begin with reinforcing any response that resembles the desired behavior. For example, parents might praise a child for picking up one toy. As...
The steps involved in shaping begin with reinforcing any response that resembles the desired behavior. For example, parents might praise a child for picking up one toy. As...
322
 01:24
01:24Reinforcement Schedules
148
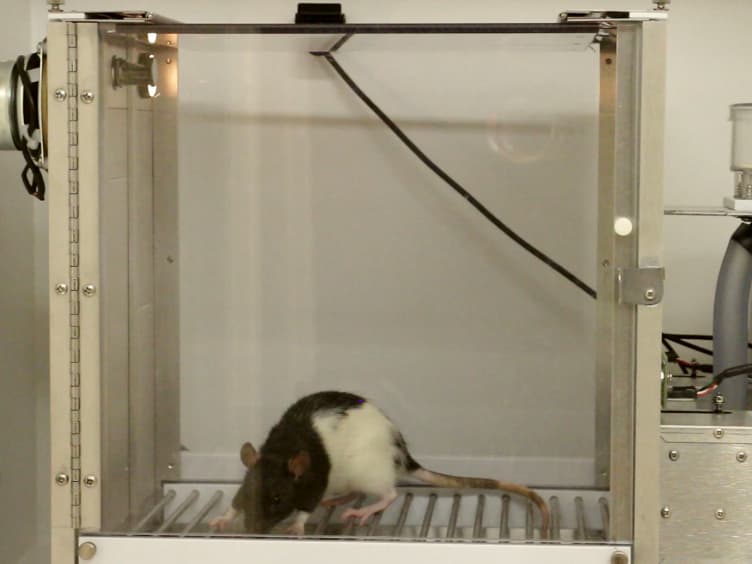
Positive reinforcement is a powerful method for teaching new behaviors to both animals and humans. B.F. Skinner demonstrated this with his experiments using rats in a Skinner box. When a rat pressed a lever, it received a food pellet. This immediate reward encouraged the rat to repeat the behavior. This method, where a reward follows every instance of the behavior, is known as continuous reinforcement. It is highly effective for establishing new behaviors quickly.
Once a behavior is learned,...
Once a behavior is learned,...
148
 01:23
01:23Reinforcement
209
Positive and negative reinforcement are key concepts in operant conditioning, a learning process where the consequences of a behavior affect the likelihood of that behavior being repeated.
Positive reinforcement occurs when a behavior is followed by the presentation of a rewarding stimulus, increasing the frequency of that behavior. For example:
Positive reinforcement occurs when a behavior is followed by the presentation of a rewarding stimulus, increasing the frequency of that behavior. For example:
209
 01:06
01:06Law of Effect
1.4K
B.F. Skinner, a prominent figure in behavioral psychology, introduced operant conditioning by emphasizing the role of consequences in shaping behavior. This theory builds upon the law of effect proposed by Edward Thorndike, which posits that behaviors followed by satisfying outcomes are likely to be repeated. In contrast, those followed by unsatisfying outcomes are less likely to recur.
Edward Thorndike's foundational work involved studying learning in animals, particularly using puzzle...
Edward Thorndike's foundational work involved studying learning in animals, particularly using puzzle...
1.4K
 01:24
01:24Generalization, Discrimination, and Extinction
559
Generalization, discrimination, and extinction are key concepts in operant conditioning that influence how behaviors are learned and maintained.
Generalization occurs when a behavior reinforced in one context is performed in similar situations. For instance, a student who studies diligently for calculus and receives excellent grades might apply the same study habits to psychology and history, expecting similar results. Generalization shows how learning in one setting can influence behavior in...
Generalization occurs when a behavior reinforced in one context is performed in similar situations. For instance, a student who studies diligently for calculus and receives excellent grades might apply the same study habits to psychology and history, expecting similar results. Generalization shows how learning in one setting can influence behavior in...
559
 01:07
01:07Elaborative Rehearsals
86
Elaborative rehearsal is a crucial cognitive strategy that strengthens information encoding in long-term memory by making meaningful connections between new data and pre-existing knowledge. This approach contrasts with maintenance rehearsal, which involves simple repetition without delving into the significance of the information. While maintenance rehearsal might temporarily keep information active in short-term memory, it is less effective for long-term retention.
The effectiveness of...
The effectiveness of...
86
您也可能阅读
相关文章
通过共同作者、期刊和引用图与本文相关的文章。
排序
Same author
Ultrastructural changes in cryopreserved tracheal grafts of sprague-dawley rats.
ASAIO journal (American Society for Artificial Internal Organs : 1992)·2009
Same author
Facile synthesis of size-tunable micro-octahedra via metal-organic coordination.
Chemical communications (Cambridge, England)·2009
Same author
N-acetyl cysteine and penicillamine induce apoptosis via the ER stress response-signaling pathway.
Molecular carcinogenesis·2009
Same author
Targeting glucosylceramide synthase downregulates expression of the multidrug resistance gene MDR1 and sensitizes breast carcinoma cells to anticancer drugs.
Breast cancer research and treatment·2009
Same author
N-glycosylation of ATF6beta is essential for its proteolytic cleavage and transcriptional repressor function to ATF6alpha.
Journal of cellular biochemistry·2009
Same author
A humanized anti-osteopontin antibody inhibits breast cancer growth and metastasis in vivo.
Cancer immunology, immunotherapy : CII·2009
Same journal
Intervention Feasible Region and Driver Risk Capacity Aware Human-Machine Collaborative Safe Trajectory Planning.
IEEE transactions on neural networks and learning systems·2026
Same journal
A Unified Differential Denoising Learning Framework With a Pre-Trained Model and Fuzzy Graph Networks for Drug-Drug Interaction Prediction.
IEEE transactions on neural networks and learning systems·2026
Same journal
Self-Supervised Continuous Dynamic Graph Representation Learning via Hawkes Processes.
IEEE transactions on neural networks and learning systems·2026
Same journal
cPU: Consistent Risk Estimator for Positive-Unlabeled Learning.
IEEE transactions on neural networks and learning systems·2026
Same journal
Tuning-Free Latent Diffusion Models for Ultrahigh-Resolution Image Editing.
IEEE transactions on neural networks and learning systems·2026
Same journal
Hidden Data Recovery and Forecasting via Next-Generation Reservoir Computing With Multiscale Delay Selection.
IEEE transactions on neural networks and learning systems·2026